-Or-
I just spent a large chunk of the evening fighting something, even after I'd come to an answer I was happy with.
The problem is fairly easy to state: given a printed page, can you reliably determine the column boundaries? The answer has to be "easily, duh," right? So, I found a bunch of newspaper images with different numbers of columns, and did some tests.
First, I wrote a program that did regular and robust statistics on a column-by-column basis, and plotted these up.
 |
| The test image. |
 |
| The normalizations are simply the mean of the given statistic. |
So that kind of looks like garbage. Without the normalization, it becomes obvious that at column gaps, the signal (the mean or median) goes up, as the intensity is brighter. However, the variance (sigma or
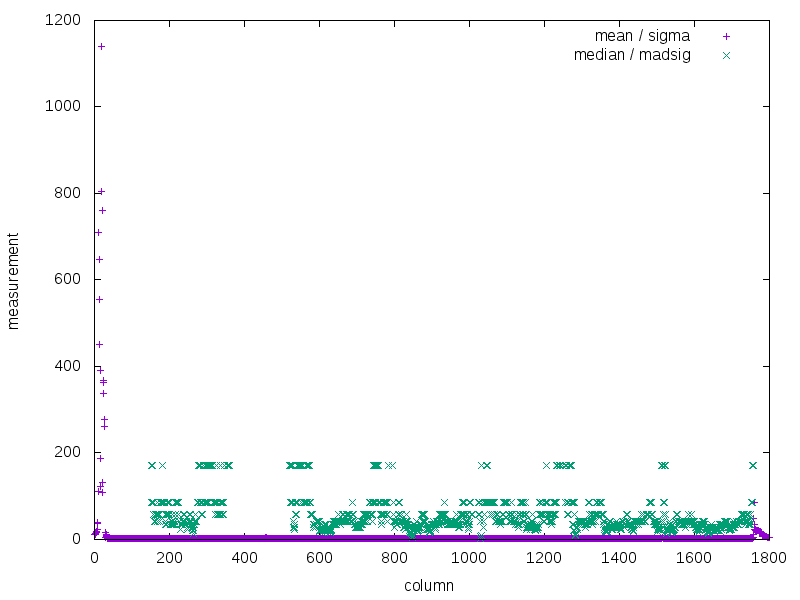
MAD-sigma) goes down, as the column becomes more uniform. Therefore, if you divide the one by the other, these two features should reinforce, and give a much clearer feature:
 |
| Which it does. |
So, applying it to the image corpus:
I probably should have kept the normalization factor, but that would require calculating them and sticking them in the appropriate places in the plot script, and I was just too lazy to do that. Still, this looks like it's a fairly decent way to detect column gaps. The robust statistics do a worse job, probably because they attempt to clean up the kind of deviations that are interesting here. Compared to the baseline level, it looks like the gaps have a factor of about 10 difference. It really only fails when the columns aren't really separated (or they might be, if I bothered normalizing the plots and clipping the range better).




{kind=link}

{kind=link}

{kind=link}

{kind=link}

{kind=link}
{kind=link}

{kind=link}
No comments:
Post a Comment